作者:长江7808 | 来源:互联网 | 2023-08-16 12:21
篇首语:本文由编程笔记#小编为大家整理,主要介绍了Apache Flink从入门到放弃——Flink简介相关的知识,希望对你有一定的参考价值。
目 录
- 1. 计算引擎的发展历史
- 2. 什么是Flink
- 2.1 概念
- 2.2 什么是有界的数据流和无界数据流?什么是状态?
- 2.3 Fink的历史
- 2.4 Flink的特点
- 2.5 Flink的应用
- 2.6 流批架构的演变
- 2.7 Flink的分层API
- 3. Flink VS Spark
- 4. Flink Or Spark ?
1. 计算引擎的发展历史
随着大数据的发展,大数据的存储、计算、运用百花齐放;而大数据的计算中最重要的就是计算引擎,时至今日,很多人将大数据引擎分为四代,分别是:
-
第一代,Hadoop承载的MapReduce,将计算分为Map和Reduce两个阶段,同时采用Hadoop集群的分布式计算原理来实现数据的计算,但是MapReduce存在很明显的缺点
1)针对多个迭代计算只能用多个Job的多次MapReduce串联完成
2)大量的中间结果要溢写到磁盘,因此存在大量的磁盘交互,效率十分低下;
-
第二代,带有DAG(Directed Acyclic Graph 有向无环图)框架的计算引擎,如Tez以及调度的Oozie,在第一代的基础上增加了DAG,但是运算效率还是达不到许多需求的要求;
-
第三代,以Spark为代表的内存计算引擎,赢得了内存计算的飞速发展,第三代计算引擎的特点是主要不仅DAG(有向无环图),也以内存为赌注,强调计算的实时性型,是目前批处理的佼佼者,给用户十分友好的体验,一度被人认为要在计算引擎上一统天下的;
-
随着实时计算需求的迫切性,各种迭代计算的性能以及对流式计算和SQL的支持,以Spark Streming为例也支持流式计算,而且能解决99%的流式计算要求,但是Spark Streaming设计理念里面认为流是批的极限,即微批(micro-batch)就是流式,所以有个致命的缺点就是攒批;因为这个缺点的存在,剩下的1%的流式运算并不太适合Spark,而Flink就很好的规避了这个缺点,认为批是流的特例,把数据计算归为有界和无界的,有界的数据就是批处理,无界的数据就是流式,而且以流批一体为终极计算目标,Flink就被归在第四类内,从这里开始时就正式揭开Flink的面纱!
2. 什么是Flink
2.1 概念
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
Apache Flink是一个分布式大数据计算引擎,可以对有界的数据和无界的数据进行有状态的计算,可部署在各种集群环境中,对各种大小数据规模进行快速计算。
什么玩意 ?着实听不懂呀,那就用自己的话说说?Flink 是一个框架,是一个数据处理的引擎;而且是分布式,是为了应付大规模数据的应用场景而诞生;另外, Flink 处理的是数据流。所以, Flink 是一个流式大数据处理引擎。而内存执行速度和任意规模,突出了 Flink 的两个特点:速度快、可扩展性强——这说的自然就是小松鼠的“快速”和“灵巧”了。
那什么叫作“无界和有界数据流”,什么又叫作“有状态计算”呢?且听下章节。
整个Flink的框架如图2.1;
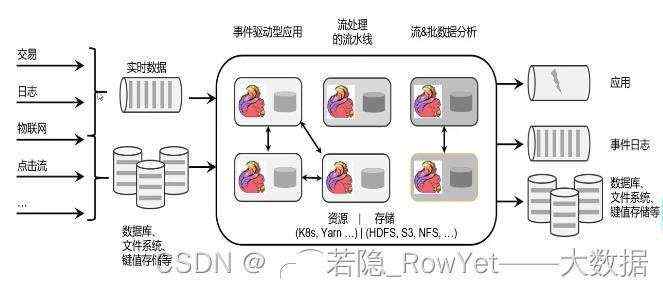
图2.1 Flink计算架构图
2.2 什么是有界的数据流和无界数据流?什么是状态?
在Flink的设计理念中,将数据分为有界数据和无界数据,如图2.2;
有界数据(Bounded data):定义了数据的开始和结束,也就是批处理的本质;无界数据(Unbounded data): 数据定义了开始,但是没有结束,因此需要连续不断的处理计算,如基于事件的有序驱动。
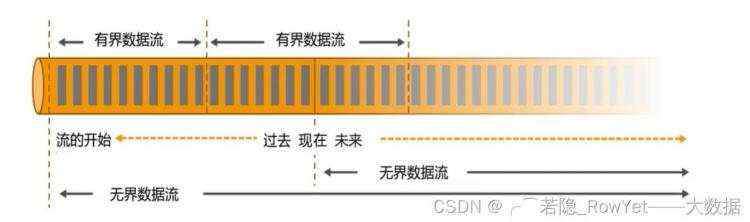
图2.2 有界数据和无界数据的处理
Flink 内置的很多算子,包括源 source,数据存储 sink 都是有状态的。在 Flink 中,状态始终与特定算子相关联。Flink 会以checkpoint的形式对各个任务的 状态进行快照,用于保证故障恢复时的状态一致性。Flink 通过状态后端来管理状态 和 checkpoint 的存储,状态后端也可以有不同的配置选择,为什么算子需要状态?
- 实现算子的逻辑(作为一种中间状态);
- 错误恢复,往往计算并不能一步到位,如果没有记录状态,一旦中单有算子出错,代表整个计算要从头算起。
2.3 Fink的历史
- 前生是
Stratosphere,是一个研究性项目,其目标是开发下一代大数据分析平台,它是由 3 所地处柏林的大学和欧洲其他一些大学在 2010~2014 年共同进行的研究项目,由柏林理工大学的教授沃克尔·马尔科(Volker Markl)领衔开发; - 2014年4月,贡献给Apache软件基金会,更名为Apache Flink;
- 2014年8月,Flink第一个版本0.6正式发布,与此同时Fink的几位核心开发者创办了Data Artisans公司;
- 2014年12月,Flink项目完成孵化,成为Apache顶级项目;
- 2015年4月,Flink发布了里程碑式的重要版本0.9.0;
- 2019年1月,长期对Flink投入研发的阿里巴巴,以9000万欧元的价格收购了Data Artisans公司;
- 2019年8月,阿里巴巴将内部版本Blink开源,合并入Flink1.9.0版本;
- 2020年5月,Apache Flink 1.10.0发布;
- 2020年7月,Apache Flink 1.11.0发布;
- 2020年12月,Apache Flink 1.12.0发布
- 2021年4月,Apache Flink 1.13.0发布;
- 2021年9月,Apache Flink 1.14.0发布;
- ……
目前2022年,生产上使用的Flink以1.12.X和1.13.X为主,看时间序列也可以知道Flink发展十分迅速,而且常年在在github的活跃度、访问量名列前茅。
2.4 Flink的特点
在德语中,flink一词表示快速、灵巧。项目的 logo 是一只彩色的松鼠,当然了,这不仅是因为 Apache 大数据项目对动物的喜好(是否联想到了 Hadoop、 Hive?),更是因为松鼠这种小动物完美地体现了快速、灵巧的特点。关于 logo 的颜色,还一个有趣的缘由:柏林当地的松鼠非常漂亮,颜色是迷人的红棕色;而 Apache 软件基金会的 logo,刚好也是一
根以红棕色为主的渐变色羽毛。于是, Flink 的松鼠 Logo 就设计成了红棕色,而且拥有一个漂亮的渐变色尾巴,尾巴的配色与 Apache 软件基金会的 logo 一致。这只松鼠色彩炫目,既呼应了 Apache 的风格,似乎也预示着 Flink 未来将要大放异彩。

图2.4.1 Flink logo
Flink 区别与传统数据处理框架的特性如下:
- 支持
java(主)和scala api(真香),新版本支持python api; - 流(dataStream)批(dataSet)一体化,支持事件处理和无序处理通过DataStreamAPI,基于DataFlow数据流模型,在不同的时间语义(事件时间,摄取时间、处理时间)下支持灵活的窗口(时间,滑动、翻滚,会话,自定义触发器;
- 支持有状态计算的Exactly-once(仅处理一次)容错保证,支持基干轻量级分布式快照checkpoint机制实现的容错,支持savepoints机制,一般手动触发,在升级应用或者处理历史数据是能够做到无状态丢失和最小停机时间;
- 兼容hadoop的mapreduce,集成YARN、HDFS、Hbase和其它hadoop生态系统的组件,支持大规模的集群模式,支持yarn、mesos。可运行在成千上万的节点上,可以连接到最常用的存储系统,如 Apache Kafka、 Apache Cassandra、Elasticsearch、JDBC、 Kinesis 和(分布式)文件系统,如 HDFS 和 S3。
- 在dataSet(批处理)API中内置支持迭代程序
- 图处理(批)机器学习(批)复杂事件处理(流)
- 自动反压机制加高可用。本身高可用的设置,加上与 K8s, YARN 和 Mesos 的紧密集成,再加上从故障中快速恢复和动态扩展任务的能力, Flink 能做到以极少的停机时间 7× 24 全天候运行,能够更新应用程序代码并将作业(jobs)迁移到不同的 Flink 集群,而不会丢失应用程序的状态。
- 高效的自定义内存管理,结果的准确性, Flink 提供了事件时间(event-time)和处理时间(processing-time)
语义。对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。 - 健壮的切换能力在in-memory和out-of-core中
- 高吞吐和低延迟。每秒处理数百万个事件,毫秒级延迟。
2.5 Flink的应用
- 批处理和流处理
- 流数据更真实地反应了我们的生活方式
- 低延时、高吞吐、结果准确和良好的容错性
- 流批一体的终极目标
基于以上优点,Flink在目前的大数据计算中简直是大红大紫,如图2.5.1,许多大厂公司的宠儿,都会用到Flink;

图2.5.1 Flink在企业中的应用
Flink有很多用途,目前而言,最佳的使用场景有哪些呢,如图2.5.2;
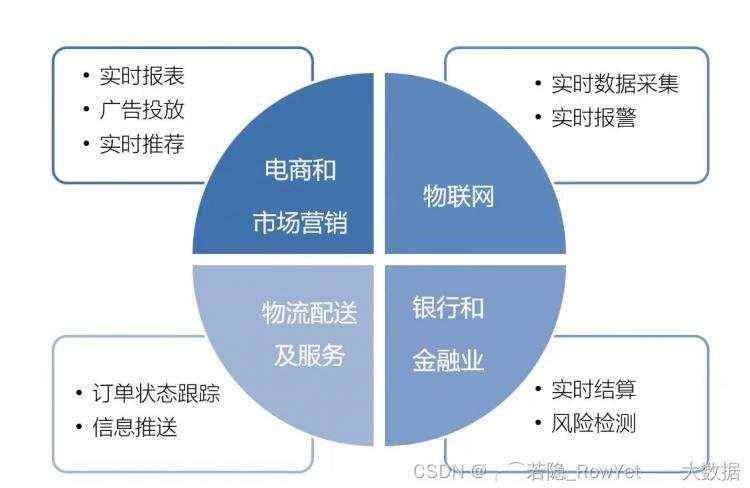
图2.5.2 Flink最佳的运用场景
2.6 流批架构的演变
- 传统关系型数据的系统架构,如mysql、SQL Server为后台数据库的OLTP系统;

图2.6.1 事务处理
- 有状态的流处理,因为传统的OLTP不太好满足OLAP的数据分析而诞生,即将应用逻辑和本地状态存在内存,同时定期存盘持久化,保证数据的不被丢失,此种框架以storm为代表,但是也存在必然缺陷,那就是数据在分布式的机器下,因为网络等不稳定因素,无法保证有序和精准的一次性消费。
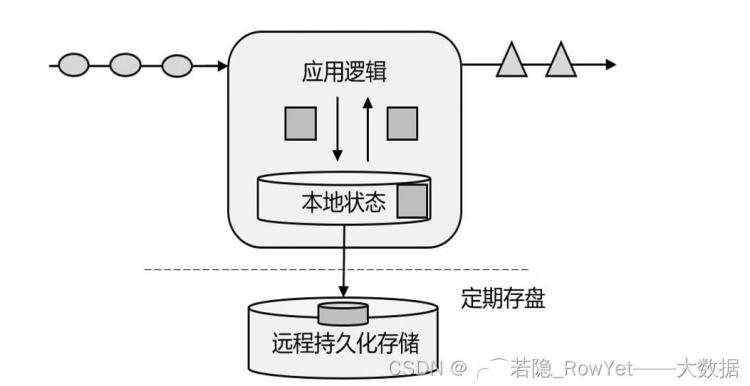
图2.6.2 有状态的流处理
- lambda架构,即用每一段时间的批处理数据刷新最新的数据,而当时最新的数据用流处理来做增量,可以理解为批处理做一次覆盖,流处理做实时增量,因为有批处理的保证,数据最终一致性得到保证,缺点是维护两套架构,工程量比较大;
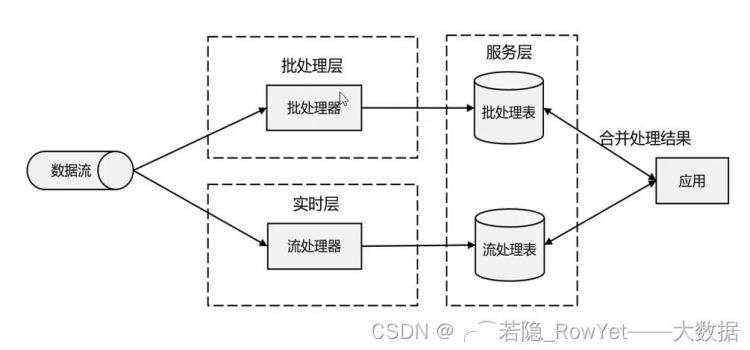
图2.6.3 lambda架构
- 实时数仓框
1)事件驱动型实时数仓,如图2.6.4,前端运用的事件触发(如点击按钮、扫码等)将关键性的数据变化写入消息队列(kafka,RabbitMQ等),然后利用Flink消费消息队列的数据进行处理,处理后的数据可以持久化存储到各大存储组件内(hive,hbase,hdfs等),也可以重新写回到消息队列内供下一个运用使用;
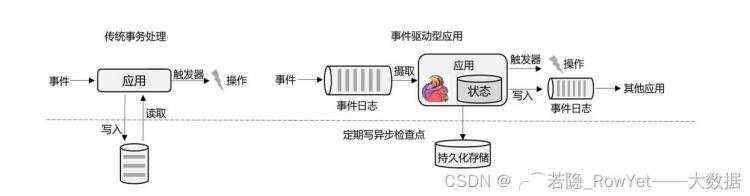
图2.6.4 事件驱动型实时数仓运用
2) 数据分析实时数仓型,如图2.6.5,主要就是通过根据OLTP系统后端数据库的change log,来实时定期更新至数据数仓的存储媒介(HDFS、Hbase、ElasticSearch、KuDu、ClickHouse)等内,再外接可视化报(apache superset)表实时呈现数据;

图2.6.5 数据分析实时数仓型
2.7 Flink的分层API
- 越顶层越抽象,表达含义越简明,使用越方便
- 越底层越具体,表达能力越丰富,使用越灵活
- Flink版本更新迭代最主要原因之一:丰富上层API的内容,让Flink越来越容易的被使用;
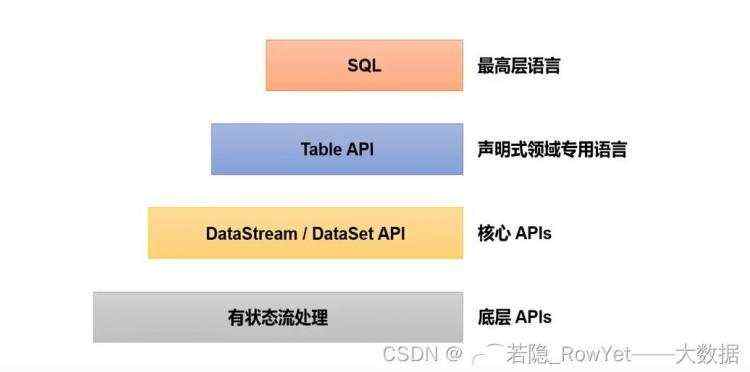
图2.7.1 Flink的分层API
3. Flink VS Spark
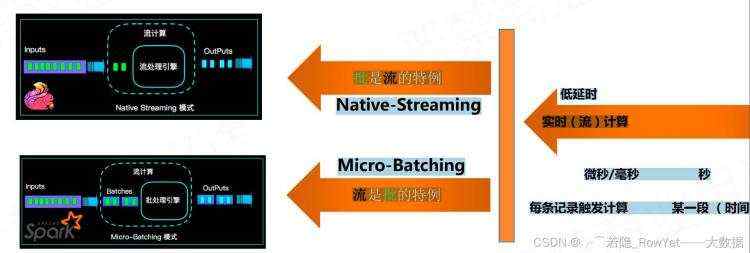
图3.1 Flink对比Spark
- 三观
1)Spark认为流是批的特例,采用微批的概念,输入数据流进来后Spark Stream将数据切割成一个个微批(Micro-batch)处理;
2)Flink将数据分为有界数据和无界数据,有界的数据就是批处理,无界的数据就是流计算;
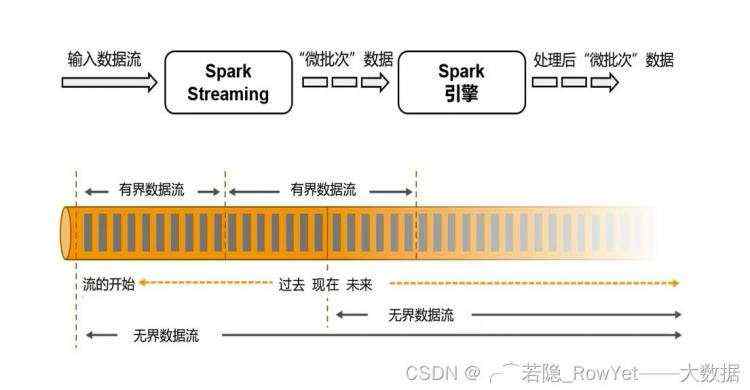
图3.2 Flink对比Spark的设计理念对比
- 数据模型 1)Spark采用RDD模型,Spark Streaming的DStream实际上也就是一组小批数据RDD的集合 2)Flink基本数据模型是数据流,以及事件(Event)序列;
- 运行时框架
1)Spark是批计算,将DAG划分为不同的stage,一个完成后才可以计算下一个;
2)Flink是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理。

图3.3 Flink对比Spark的运行时框架对比
4. Flink Or Spark ?
Spark 和 Flink 可以说目前是各擅胜场,批处理领域 Spark 称王,而在流处理方面 Flink 当仁不让。具体到项目应用中,不仅要看是流处理还是批处理,还需要在延迟、吞吐量、可靠性,以及开发容易度、公司IT能力等多个方面进行权衡。
那如果现在要学习一门框架的话,优先选 Spark 还是 Flink 呢?其实我们可以看到,不同的框架各有利弊,同时它们也在互相借鉴、取长补短、不断发展,至于未来是 Spark 还是 Flink、甚至是其他新崛起的处理引擎一统江湖,都是有可能的
,咱们就且看今日之域中,尽是谁家之天下?
作为技术人员,我们应该对不同的架构和思想都有所了解,跳出某个框架的限制,才能看到更广阔的世界。到底 Spark 还是 Flink?——小孩子才做选择题!大人当然是全都要啦,博主的建议,目前还是比较倾向于离线批处理选Spark,流计算首选Flink。








 京公网安备 11010802041100号
京公网安备 11010802041100号